
Politicians are So Keen on Open Access. But why?
People sometimes speculate on why policymakers, including elected politicians, are so keen on open access (i.e. giving people free access to the output of researchers – especially taxpayer-funded research), which has made enormous strides in recent years.
It may seem obvious to some readers of this blog, although there are various different potential reasons, such as a desire to ensure research undertaken in the UK is widely cited and wanting to help small businesses find out about the latest research. But there is another – more mundane – reason that is often overlooked.
In their day-to-day policy work, politicians and their advisers can find it hard to access academic research themselves. They have no institutional log-ins and, while the Libraries of the House of Commons and the House of Lords subscribe to some journals, it is an eclectic and seemingly random list. If you want to know why policy is not always rooted in evidence, this is one small reason why. Civil servants face a similar challenge. When I was a special adviser, and therefore a temporary civil servant, I had no routine access to the output of peer-reviewed journals, even though research came within my Minister’s brief. Occasionally, I would ask to see a specific article and, although the department did usually end up buying it eventually, it was a tortuous and time-consuming process as no one ever knew which budget should cover the cost (normally around £25).
Some evidence on this problem was offered in a speech by David Willetts when he was the Universities and Science Minister. He spoke about the challenges he faced when writing a book before taking ministerial office: I had my own experience of being an outsider when I was writing my book, ‘The Pinch’, on fairness between the generations. It was very frustrating to track down an article drawing on publicly funded research and then find it hidden behind a pay wall. That meant it was freely accessible to a professional in an academic institution, but not to me as an independent writer. That creates a barrier between the academic community, the insiders, and the rest of us, which is deeply unhealthy.
It may be that the Westminster and Whitehall authorities should have fixed this issue in the past, in the interests of good public policy and proper scrutiny of the executive by the legislature, by paying publishers properly for access to more journals in the way university libraries paid (and pay)…but I still can’t help thinking the single thing those who dislike open access could have done to slow its pace would have been to have given generous terms to policymakers a long time ago.

Since the inception of open access movements in the early 2000s, many things have happened around the scientific community and the scholarly publishing world. Universities and research institutions have gradually embraced the principles of open access and hence put institutional repositories in place. Many of them are European and American universities, though. Countries have adopted open access policies which required all tax payers funded researches accessible free of charge for end users.
Despite initial resistance to the movement, heavy weight scholarly publishers such as Elsevier and Nature have shown, though it is limited, interest at least for the time being to go with hybrid model of journal publishing. Publishers that adopt hybrid model have both open access and access restricted journal articles. Those classic publishers use a mix of gold open access approach and embargo terms to give limited access to some articles that they publish in an open access environemnt. With the first one, they charge article processing charges (APC), authors pay the publishers for the article they publish on one of their scientific journals so as to give end users free access to the published articles. This is Gold open access approach- here authors carry burden that comes with article publishing and dessimination.
The second approach is which is embargo period a way through which end users access articles free of charge once embargo period is lifted- embargo period usually lasts for one year. While papers are under embargo period, access to those articles is only possible through subscription.
Open access movement is growing. Open access journals are flourishing-both in developed and developing countries. Yet still, after more than a decade long journal with theories and practices of open access, many remained skeptical about the quality of open access journals. The cynics are not silenced despite gains made and quality demonstrated by major players in the field: BioMed and PlosOne managed to build trust and gain confidence from the scientific community. The number of open access citation and download has shown remarkable increase. Their impact factor has improved significantly. Though, all open access journals are not of the same standard and do not adhere to strict scientific articles publishing code of conduct such as undergoing rigorous peer-review process.
For more on this subject read an article from the Economist.
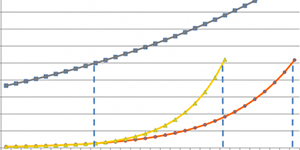
Open Access Journals Revenue will triple by 2017
Simba Information has found out that the number of Open Access (OA) publishers and the revenue the sector generates has shown remarkable growth. This is mainly in the area of science, technical and medical (STM) journal publishers. The result has been achieved as a result of intensive global campaign by scientists, librarians, research funders and universities- according to Simba Information.
Samba Information estimates show that revenue of Open Access publishers increased by 32.8% in 2013. The revenue is principally generated through article processing charges (APC) that authors pay publishers in order to publish their articles on an Open Access journals.
Despite this rapid growth, OA revenue still only represents 2.3% of global 2013 STM journal sales, according to Simba Information’s research. But this revenue stream is a bright spot against a flat market. While STM journal revenue is expected to increase at a compound annual rate of between 1% and 2% between 2011 and 2017, OA revenue is expected to more than triple in that period.
Open access is already having a bigger impact in terms of publishing output. By some estimates, OA already represents 10% to 20% of all research articles published.

Some researchers have concerns about the quality of open access journals. Those concerns mainly stem from open access journals’ perceived low quality peer-review process and their low impact factor: both are highly valued quality measures in the scientific community circles.
Publishing on Open access journals is a newly emerged approach of disseminating and giving access to scientific research outputs. In most cases most of high standard open access journals are 10 to 12 years old. They are immature in many senses and it’s very plausible to assume that (it’s also quite evident) they have low impact factor. To be honest it is not the right way to compare newly emerging journals impact factor with well established and industry leading classic scientific journals impact factor. High impact factor is still something which is highly associated with non-open access journals such as Nature and Science.
One of the most frequently raised concern in the scientific community, based on peer-review and impact factor, is whether a researcher can build promising career (tenure concern) by publishing on open access journals. So, does publishing on open access journals hurt researchers’ tenure? Jenny Blair’s article tries to answer this very question.
……………………………………………………………
Michael Eisen is a professor of genetics at the University of California, Berkeley. He’s a Howard Hughes Medical Investigator. He juggles over a dozen graduate students and postdocs. Yet his lab has never published a paper in Science, Nature, Cell, The Lancet or the New England Journal of Medicine. None appear in traditional high-impact genetics journals, either.
Instead, the lab’s papers appear only in open-access journals – those that are available to read online and free from financial “tolls” such as paywalls, subscriptions or other barriers restricting their audience – something the traditional journals can’t always boast.
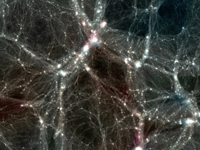
A small team of astrophysicists and computer scientists have created some of the highest-resolution snapshots yet of a cyber version of our own cosmos. The data which is a result of one of the largest and most sophisticated cosmological simulations is now open to public. People can observe it and researchers can use it to develop their theories and conduct varies kind of astrological and cosmological researches.
………………………………………………………………………………..
A small team of astrophysicists and computer scientists have created some of the highest-resolution snapshots yet of a cyber version of our own cosmos. Called the Dark Sky Simulations, they’re among a handful of recent simulations that use more than 1 trillion virtual particles as stand-ins for all the dark matter that scientists think our universe contains.
They’re also the first trillion-particle simulations to be made publicly available, not only to other astrophysicists and cosmologists to use for their own research, but to everyone. The Dark Sky Simulations can now be accessed through a visualization program in coLaboratory, a newly announced tool created by Google and Project Jupyter that allows multiple people to analyze data at the same time.
To make such a giant simulation, the collaboration needed time on a supercomputer. Despite fierce competition, the group won 80 million computing hours on Oak Ridge National Laboratory’s Titan through the Department of Energy’s 2014 INCITE program.
In mid-April, the group turned Titan loose. For more than 33 hours, they used two-thirds of one of the world’s largest and fastest supercomputers to direct a trillion virtual particles to follow the laws of gravity as translated to computer code, set in a universe that expanded the way cosmologists believe ours has for the past 13.7 billion years.
“This simulation ran continuously for almost two days, and then it was done,” says Michael Warren, a scientist in the Theoretical Astrophysics Group at Los Alamos National Laboratory. Warren has been working on the code underlying the simulations for two decades. “I haven’t worked that hard since I was a grad student.”
Back in his grad school days, Warren says, simulations with millions of particles were considered cutting-edge. But as computing power has increased, particle counts did too. “They were doubling every 18 months. We essentially kept pace with Moore’s Law.”
When planning such a simulation, scientists make two primary choices: the volume of space to simulate and the number of particles to use. The more particles added to a given volume, the smaller the objects that can be simulated-but the more processing power needed to do it.
Current galaxy surveys such as the Dark Energy Survey are mapping out large volumes of space but also discovering small objects. The under-construction Large Synoptic Survey Telescope “ill map half the sky and can detect a galaxy like our own up to 7 billion years in the past,” says Risa Wechsler, Skillman’s colleague at KIPAC who also worked on the simulation. “We wanted to create a simulation that a survey like LSST would be able to compare their observations against.”
The time the group was awarded on Titan made it possible for them to run something of a Goldilocks simulation, says Sam Skillman, a postdoctoral researcher with the Kavli Institute for Particle Astrophysics and Cosmology, a joint institute of Stanford and SLAC National Accelerator Laboratory. “We could model a very large volume of the universe, but still have enough resolution to follow the growth of clusters of galaxies.”
The end result of the mid-April run was 500 trillion bytes of simulation data. Then it was time for the team to fulfill the second half of their proposal: They had to give it away.
They started with 55 trillion bytes: Skillman, Warren and Matt Turk of the National Center for Supercomputing Applications spent the next 10 weeks building a way for researchers to identify just the interesting bits-no pun intended-and use them for further study, all through the Web.
“The main goal was to create a cutting-edge data set that’s easily accessed by observers and theorists,” says Daniel Holz from the University of Chicago. He and Paul Sutter of the Paris Institute of Astrophysics, helped to ensure the simulation was based on the latest astrophysical data. “We wanted to make sure anyone can access this data-data from one of the largest and most sophisticated cosmological simulations ever run-via their laptop.”
Source Symmetrymagazine